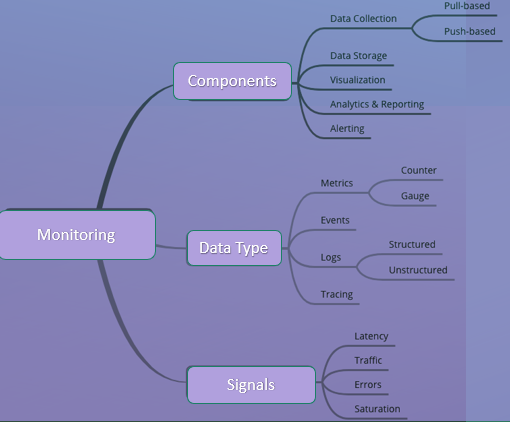
Introduction
Amazon
CloudWatch is a monitoring service offered by Amazon Web Services (AWS) that is
used to monitor resources and applications on the AWS platform. It provides
real-time and historical data on system and application performance, allowing
users to identify and troubleshoot issues quickly. In this guide, we’ll provide
an overview of Amazon CloudWatch and explain how to use it.
What
is Amazon CloudWatch?
Amazon
CloudWatch is a monitoring service that provides data and insights into system
and application performance. It collects and tracks metrics, logs, and events
for AWS resources such as EC2 instances and Amazon RDS databases. Additionally,
CloudWatch can monitor custom metrics generated by your own applications or
services. The data collected provides insights into application performance,
resource utilization, and operational health.
Why
Use Amazon CloudWatch?
Using
Amazon CloudWatch can help identify and resolve issues quickly. As it provides
real-time and historical data, monitoring with CloudWatch can help ensure
applications are running smoothly and are not experiencing performance issues.
By monitoring performance metrics, it’s possible to identify bottlenecks and
trends early, before they become major issues.
Using
Amazon CloudWatch
We
have divided using Amazon CloudWatch into several sections to provide a better
understanding of the service.
Getting
Started
To
use Amazon CloudWatch, you first need to create an AWS account. Once you have
an account, you can access CloudWatch through the AWS web console or
programmatically using the AWS API.
Amazon
CloudWatch Concepts
Amazon
CloudWatch uses the following concepts:
Metrics
A
metric is a measure of a specific resource or application performance that is
collected by CloudWatch. Metrics can be collected automatically for many AWS
resources, such as EC2 instances or RDS databases. Alternatively, custom
metrics can be defined.
Namespaces
A
namespace is a container for CloudWatch metrics and is used to group related
metrics. AWS services automatically collect metrics in their own namespaces,
and custom namespaces can also be defined.
Dimensions
A
dimension is a name-value pair that helps identify a specific instance of a
metric. Dimensions are used to uniquely identify a metric, and multiple
dimensions can be used to further differentiate the metric.
Statistics
Statistics
represent the values that are collected for a metric over a period of time,
such as the minimum, maximum, average, and sum.
Creating
Metrics in Amazon CloudWatch
To
create metrics in Amazon CloudWatch, you can either use the AWS Management
Console or programmatically using the AWS API. The metric data can either be
collected automatically by CloudWatch or pushed to it using an API. CloudWatch
also allows users to define custom metrics.
Setting
up Metric Filters
Metric
filters are used to search for information in log data and then count or
aggregate the matches found. Metric filters can be used to create custom
metrics, which can be used as alarms or can be visualized in CloudWatch
dashboards.
Creating
Alarms
CloudWatch
alarms can be used to notify when a metric breaches a defined threshold, such
as when the CPU utilization of an EC2 instance exceeds a certain percentage.
When a metric passes a threshold, an alarm state is triggered and can be used
to execute an action, such as sending an email notification.
Visualizing
Metrics in Amazon CloudWatch
CloudWatch
metrics can be visualized using the AWS Management Console. Dashboards can be
created to display multiple metrics in a single view.
Creating
Dashboards
Dashboards
provide a single pane of glass view into the health and performance of your AWS
resources. Custom dashboards can be created and shared with team members,
allowing everyone to view metric data in a common format.
Customizing
Dashboards
Custom
dashboards can be configured to display the data that is most relevant to your
organization. Multiple widgets, ranging from text boxes and alarms to graphs
and time series data, can be added to a dashboard.
Monitoring
with Amazon CloudWatch
CloudWatch
provides insight into the performance of AWS resources and applications. It can
also gather data from third-party tools via log data. Real-time and historical
data can be analyzed to identify trends and performance patterns.
Using
Logs
CloudWatch
logs enable users to store, monitor, and access log files from Amazon EC2
instances. Logs can be used to monitor application and system performance,
troubleshoot issues, and identify trends.
Setting
up Log Groups
Log
groups are used to store log data. Log groups can be used to store logs for
multiple Amazon EC2 instances, as well as for applications running on AWS
Lambda.
Creating
Metrics from Logs
Metrics
can be generated from log data, allowing users to monitor performance and
identify trends that may not be evident from the raw log data.
Using
Amazon CloudWatch with Other Amazon Services
Amazon
CloudWatch can be integrated with other AWS services to provide more insight
into resources and applications:
Amazon
EC2
Amazon
EC2 instances can be monitored using CloudWatch, allowing users to track CPU
utilization, disk activity, and other performance metrics.
Amazon
RDS
Amazon
RDS databases can be monitored using CloudWatch, allowing users to track a
database's CPU utilization, free storage space, and other performance metrics.
AWS
Lambda
AWS
Lambda functions can be monitored using CloudWatch. Default metrics include
function duration, number of invocations, and error counts. Custom metrics can
also be defined.
Amazon
CloudWatch Best Practices
To
get the most out of Amazon CloudWatch, follow these best practices:
Monitoring
Amazon CloudWatch Costs
CloudWatch
pricing is based on the number of metrics, alarms, and custom events.
Understanding CloudWatch pricing can help optimize usage and lower costs.
Setting
Up Notifications for Alarms
Notifications
can be set up to alert users when an alarm enters a state. To prevent alert
fatigue, users should set up notifications carefully, ensuring that alerts are
only sent when they are necessary.
Using
AWS Auto Scaling with Amazon CloudWatch
AWS
Auto Scaling can be used with CloudWatch to automatically scale resources up or
down based on predefined thresholds.
Backing
up Amazon CloudWatch Data
Amazon
CloudWatch data should be backed up to ensure that data is not lost in the
event of a service disruption or outage.
FAQs
Here
are some frequently asked questions about Amazon CloudWatch:
What
is the pricing model for Amazon CloudWatch?
CloudWatch
pricing is based on the number of metrics, alarms, and custom events.
What
metrics can be monitored with Amazon CloudWatch?
CloudWatch
can monitor a wide variety of metrics for AWS resources, including EC2
instances, RDS databases, and Lambda functions. Custom metrics can also be
defined.
Can
I use Amazon CloudWatch with non-AWS services?
Amazon
CloudWatch can only be used with AWS resources.
Conclusion
Amazon
CloudWatch is a powerful tool for monitoring AWS resources and applications. By
providing real-time and historical data, CloudWatch can help identify and
troubleshoot issues quickly. By following best practices, CloudWatch can be
optimized to reduce costs and provide the greatest insight into system and
application performance.