Introduction to monitoring metrics
Monitoring metrics are quantitative measurements used to track and assess the performance, availability, and health of systems, applications, networks, and other components in a technology environment. These metrics provide valuable insights into the behavior and characteristics of the monitored entities, enabling effective monitoring, troubleshooting, and decision-making. Here's an introduction to monitoring metrics:
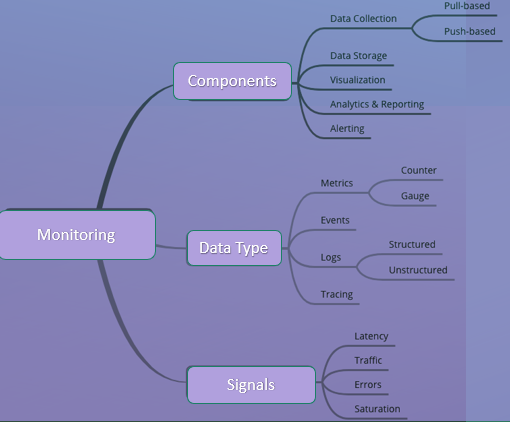
Performance Metrics:
Performance metrics measure the efficiency and effectiveness of systems and applications. Examples include:
- Response Time: The time taken to respond to a request or complete an operation.
- Throughput: The rate at which a system or application processes transactions or data.
Availability Metrics:
Availability
metrics track the accessibility and uptime of systems and services. Examples
include:
- Uptime: The percentage of time a system or service is operational and accessible.
- Downtime: The duration or frequency of system or service unavailability.
- Mean Time Between Failures (MTBF): The average time between system or service failures.
- Mean Time to Repair/Recovery (MTTR): The average time required to restore a system or service after a failure.
- Service Level Agreement (SLA) Compliance: The extent to which a system or service meets the agreed-upon performance and availability targets.
- Error and exception metrics quantify the occurrence and impact of errors or exceptional events. Examples include:
- Error Rates: The frequency or percentage of errors encountered during system or application operations.
- Exception Counts: The number of exceptional events or error conditions encountered.
- Error Response Time: The time taken to handle and recover from errors or exceptions.
- Error Code Breakdown: The distribution and frequency of different error codes or categories.
- Error Trends: The analysis of patterns or trends of errors over time to identify recurring issues.
Capacity
and Utilization Metrics:
- CPU Utilization: The percentage of CPU resources utilized over a given time.
- Memory Utilization: The percentage of memory (RAM) used by a system or process.
Security metrics assess the effectiveness and compliance of security measures. Examples include:
- Compliance Violations: The instances of violations of security policies, regulations, or industry standards.
These are just a few examples of the broad range of monitoring metrics available. The specific metrics used will vary based on the technology stack, operational requirements, and the goals of the monitoring strategy. Effective monitoring involves selecting and monitoring relevant metrics, establishing baseline values, setting appropriate thresholds, and leveraging these metrics to identify trends, anomalies, and areas for improvement in the technology infrastructure.
Monitoring
data collection techniques
Monitoring data collection techniques are employed to gather relevant data from various sources in order to monitor and analyze the performance, availability, and behavior of systems and applications. Here are some common techniques used for monitoring data collection:
- Agents or monitoring software components are installed on the target systems or applications.
- Agents collect data locally from the system's resources, such as CPU usage, memory utilization, disk I/O, network traffic, and application-specific metrics.
- The collected data is sent to a centralized monitoring system for storage, analysis, and visualization.
Remote
Monitoring:
SNMP (Simple Network Management Protocol):
- SNMP is a protocol used for managing and monitoring devices on IP networks.
- SNMP-enabled devices expose management information through SNMP, which can be queried to collect data such as CPU utilization, memory usage, network statistics, and device-specific metrics.
- SNMP managers retrieve the data from SNMP agents running on the monitored devices.
Log
Collection:
- Logs contain valuable information about system activities, errors, and events.
- Log collection involves aggregating logs from various sources, such as system logs, application logs, event logs, and web server logs.
- Tools like log forwarders, log shippers, or log collection agents are used to collect logs and send them to a centralized log management system or SIEM (Security Information and Event Management) platform.
Performance
Counters and APIs:
- Operating systems and applications often provide performance counters and APIs that expose internal metrics and statistics.
- Performance counters, such as CPU usage, memory usage, disk I/O, and network traffic, can be accessed and queried using APIs or command-line tools.
- Monitoring tools leverage these APIs to collect relevant performance data.
Packet
Sniffing:
- Packet sniffing involves capturing and analyzing network packets to gather information about network traffic, protocols, and application-level data.
- Monitoring tools or packet capture utilities are used to capture packets from the network interface for analysis.
- This technique helps in understanding network behavior, identifying network bottlenecks, and detecting anomalies or security threats.
Tracing
and Instrumentation:
- Distributed tracing techniques are employed to trace requests as they flow through various components and services of a system.
- Instrumentation involves embedding code or using frameworks to capture specific events, metrics, or logs within an application.
- Tracing and instrumentation provide detailed visibility into request flows, latency, and dependencies among system components.
These
data collection techniques can be used individually or in combination based on
the monitoring requirements and the characteristics of the systems and
applications being monitored. The selection of specific techniques depends on
factors such as the nature of the environment, available resources, and the
desired level of monitoring granularity.
Time series data refers to a sequence of data points collected and recorded over successive time intervals. This data is often used to analyze trends, patterns, and changes over time. Metric visualization involves presenting time series data in a visual format to facilitate understanding and interpretation. Here are some key aspects of time series data and metric visualization:
Time Series Data:
Time Stamps: Each data point in a time series is associated with a specific time stamp, indicating when the data was collected.
- Sampling Frequency: The frequency at which data points are collected and recorded (e.g., per second, minute, hour, day).
- Numeric Values: Time series data typically consists of numeric values that represent various metrics, such as CPU usage, network traffic, or application response times.
- Multiple Metrics: Time series data can include multiple metrics recorded simultaneously, allowing for comparative analysis and correlation.
Metric
Visualization:
- Line Charts: Line charts are commonly used to visualize time series data. Each data point is plotted as a point on the chart, and lines connect the points to show the trend over time.
- Area Charts: Similar to line charts, area charts display the trend of time series data, with the area between the line and the x-axis filled to emphasize the data's magnitude.
- Bar Charts: Bar charts can be used to represent discrete data points at specific time intervals. Each bar represents a data point, and the height of the bar corresponds to the metric value.
- Sparklines: Sparklines are compact line charts that are often embedded within tables or text to provide a quick overview of the trend without requiring a separate chart.
- Heatmaps: Heatmaps use color gradients to represent metric values over time. Darker shades indicate higher values, allowing for easy identification of patterns and anomalies.
- Gauge Charts: Gauge charts are circular or semicircular visualizations that represent a metric's value within a specified range or threshold.
- Dashboards: Metric visualization is often combined into a dashboard that presents multiple charts and metrics on a single screen, providing a comprehensive view of system performance and trends.
- Zooming and Paning: Interactive visualization tools allow users to zoom in and pan across time periods to focus on specific intervals or explore data in detail.
- Filtering and Aggregation: Users can apply filters and aggregations to slice and dice the data, allowing for analysis of specific subsets or summaries of the time series.
- Annotations and Events: Annotations and events can be added to the visualizations to mark significant occurrences, such as system upgrades, incidents, or maintenance windows.
Effective time series data visualization helps users understand patterns, identify anomalies, and make data-driven decisions. It enables quick analysis of trends, comparisons between metrics, and identification of correlations and dependencies. Visualization tools and platforms often provide various customization options and features to enhance the visual representation and analysis of time series data
Aggregation, filtering, and sampling of monitoring data
Aggregation, filtering, and sampling are essential techniques used to process and analyze monitoring data effectively. Here's an overview of each technique:
- Aggregation involves combining multiple data points into a summarized representation, reducing the volume of data while preserving key information.
- Aggregating data allows for higher-level insights and analysis by grouping data over specific time intervals or based on certain criteria.
- Common aggregation techniques include averaging, summing, counting, minimum/maximum value determination, percentiles, and histograms.
- Aggregation helps to reduce noise, smooth out fluctuations, and highlight meaningful trends in monitoring data.
Filtering:
- Filtering allows you to selectively include or exclude specific data points or subsets of data based on predefined criteria or conditions.
- Filters can be applied based on various parameters, such as time range, specific metrics or metric values, tags or labels, or other attributes associated with the data.
- Filtering enables targeted analysis and investigation by narrowing down the data set to the most relevant and meaningful information.
Sampling:
- Sampling involves selecting a subset of the monitoring data to represent the entire dataset accurately.
- Sampling reduces the computational and storage requirements for processing large volumes of data, especially in cases where real-time analysis or historical analysis is involved.
- Various sampling techniques can be used, such as random sampling, systematic sampling, or stratified sampling, depending on the desired data representation and statistical properties.
- Sampling balances the trade-off between accuracy and resource efficiency, allowing for analysis of a representative subset of data.
These techniques can be used in combination to process monitoring data efficiently. For example, aggregation can be performed after filtering or sampling to obtain summarized insights on a specific subset of data. By applying filters and sampling, you can focus analysis on specific time ranges, specific metrics of interest, or subsets of data based on relevant criteria.
The choice of aggregation, filtering, and sampling techniques depends on factors such as the characteristics of the monitoring data, the analysis goals, resource constraints, and the desired level of detail and accuracy. It is important to strike a balance between data reduction for efficiency and preserving critical information for meaningful analysis.







